数据开发
创建 SQL 作业
-
在目标工作空间选择数据开发 > 作业开发,进入作业开发页面。
-
点击创建作业,进入创建作业页面。
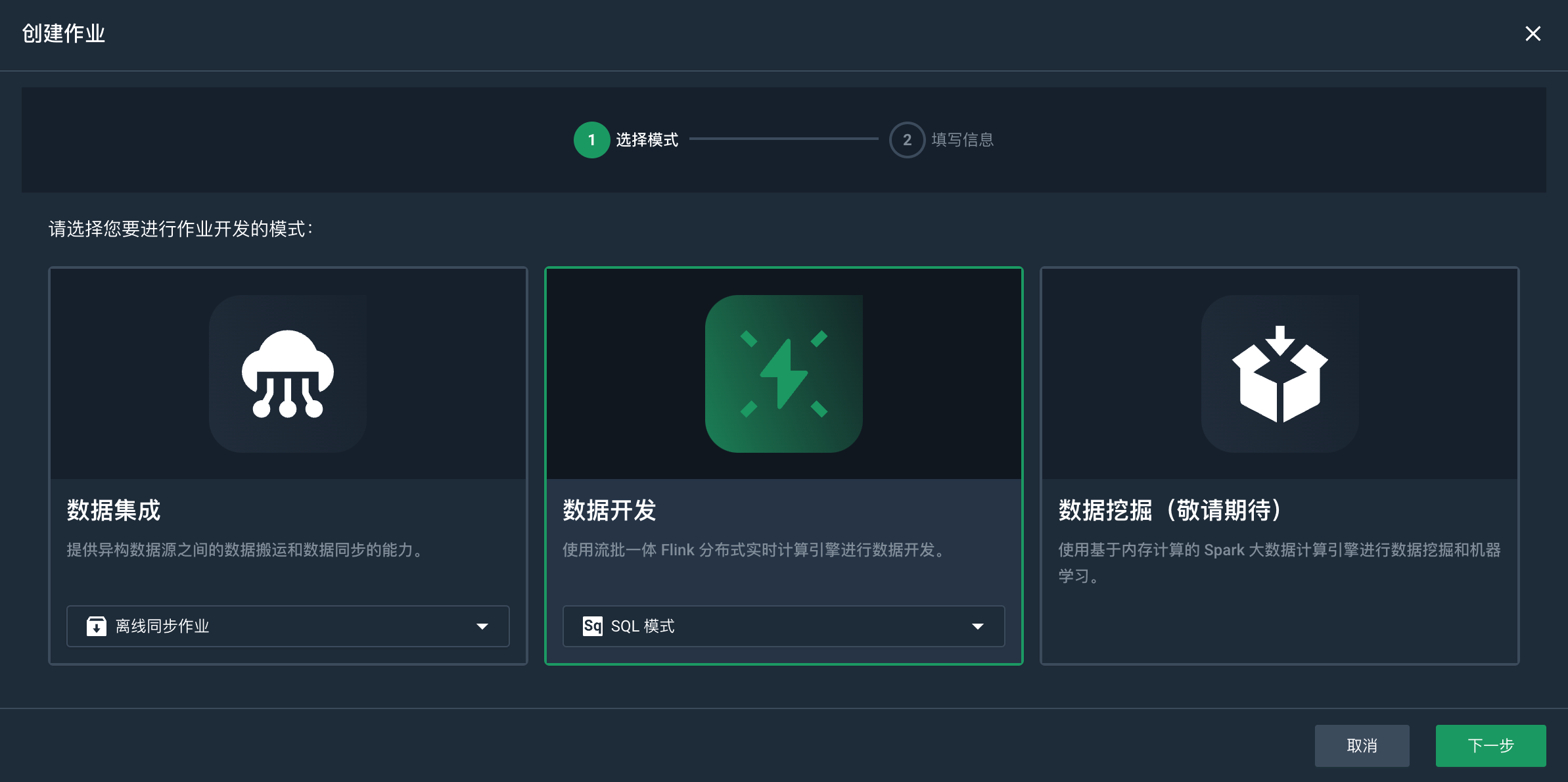
-
选择 SQL 模式。
-
点击下一步,填写作业名称,并选择作业依赖的计算集群。
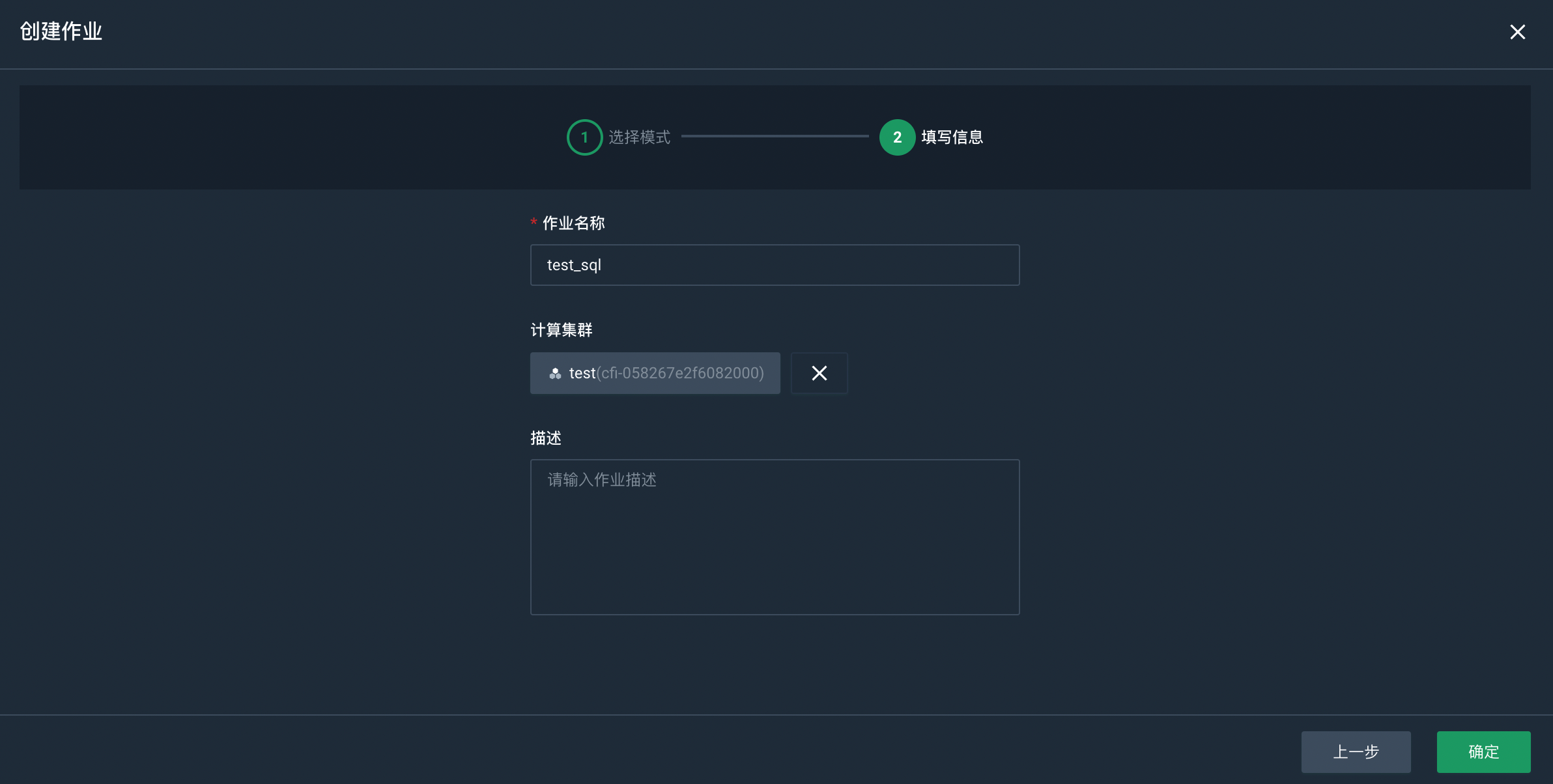
-
配置完成后,点击确定,开始创建作业。
作业创建完成后,默认进入该作业的开发面板。
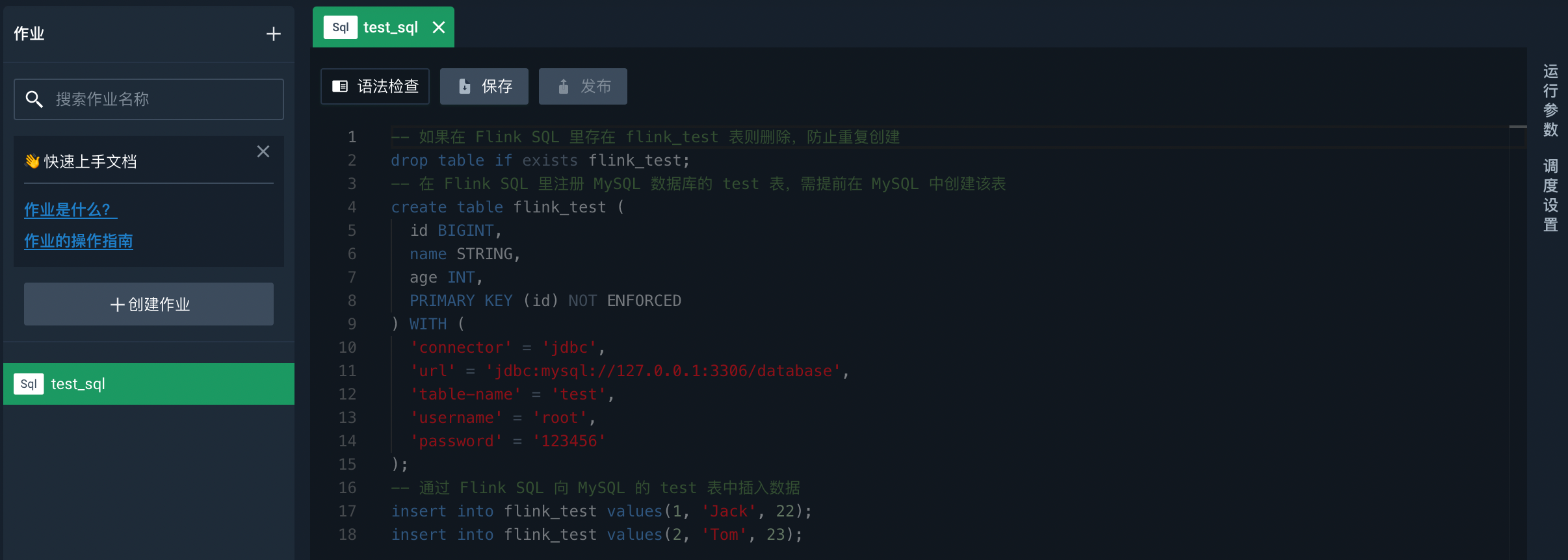
开发 SQL 作业
-
在开发面板中输入以下 SQL 代码,数据源相关参数请根据代码中的注释进行修改。
说明
更多相关参数请参见 Kafka 和 ClickHouse。
DROP TABLE IF EXISTS page_view; CREATE TABLE page_view ( product_id INT, sex INT, province STRING, full_name STRING, click_time TIMESTAMP(3), WATERMARK FOR click_time AS click_time - INTERVAL '4' SECOND ) WITH ( 'connector' = 'faker', -- 必选参数,固定值为faker 'fields.product_id.expression' = '#{number.numberBetween ''1'',''100''}', 'fields.sex.expression' = '#{regexify ''(0|1){1}''}', -- 针对sex字段随机生成0、1两种值,用于后续通过性别统计 'fields.province.expression' = '#{regexify ''(河北省|山西省|辽宁省|吉林省|黑龙江省|江苏省|浙江省|安徽省|福建省|江西省|山东省|河南省|湖北省|湖南省|广东省|海南省|四川省|贵州省|云南省|陕西省|甘肃省|青海省|台湾省){1}''}',-- 针对province字段随机生成省份,用于后续通过省份统计 'fields.full_name.expression' = '#{regexify ''(华为智慧屏V65i 65英寸 HEGE-560B 4K全面屏智能电视机 多方视频通话 AI升降摄像头 4GB+32GB 星际黑|Redmi 10X 4G Helio G85游戏芯 4800万超清四摄 5020mAh大电量 小孔全面屏 128GB大存储 4GB+128GB 冰雾白 游戏智能手机 小米 红米|小米10 至尊纪念版 双模5G 骁龙865 120HZ高刷新率 120倍长焦镜头 120W快充 8GB+128GB 透明版 游戏手机|小米10 至尊纪念版 双模5G 骁龙865 120HZ高刷新率 120倍长焦镜头 120W快充 12GB+256GB 陶瓷黑 游戏手机|Redmi 10X 4G Helio G85游戏芯 4800万超清四摄 5020mAh大电量 小孔全面屏 128GB大存储 4GB+128GB 冰雾白 游戏智能手机 小米 红米|华为 HUAWEI P40 麒麟990 5G SoC芯片 5000万超感知徕卡三摄 30倍数字变焦 8GB+128GB亮黑色全网通5G手机|Apple iPhone 12 (A2404) 64GB 黑色 支持移动联通电信5G 双卡双待手机|华为 HUAWEI P40 麒麟990 5G SoC芯片 5000万超感知徕卡三摄 30倍数字变焦 6GB+128GB冰霜银全网通5G手机){1}''}', -- 针对full_name字段随机生成产品名,用于后续通过产品名热词拆分 'fields.click_time.expression' = '#{date.past ''6'',''1'',''SECONDS''}', -- 针对click_time 字段随机生成比当前时间有1-6秒的延迟的时间数据 'rows-per-second' = '50' ); DROP TABLE IF EXISTS kafka_page_view; CREATE TABLE kafka_page_view( product_id INT, sex STRING, province STRING, full_name STRING, click_time TIMESTAMP(3), WATERMARK FOR click_time AS click_time - INTERVAL '2' SECOND ) WITH ( 'connector' = 'kafka', -- 必选参数, 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'page_view_20220120', -- 必选参数, 指定kafka topic 'scan.startup.mode' = 'latest-offset', -- 非必须参数,默认为group-offset消费组的offset。指定latest-offset为读取topic下最新的数据 'properties.bootstrap.servers' = '172.16.10.27:9092,172.16.10.28:9092,172.16.10.30:9092', -- 必选参数, 指定kafka brokers 'properties.group.id' = 'record', -- 必选参数, 指定 Group ID 'format' = 'json', -- 必选参数, 选择value消息的序列化格式 'json.ignore-parse-errors' = 'true', -- 非必选参数, 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 非必选参数, 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null ); DROP TABLE IF EXISTS clickhouse_key_words; CREATE TABLE clickhouse_key_words( province STRING, sex STRING, word STRING, stt TIMESTAMP(3), edt TIMESTAMP(3), ct BIGINT ) WITH ( 'connector' = 'clickhouse', 'url' = 'jdbc:clickhouse://172.16.10.246:8123/pk', -- 可配置集群地址,写入时随机选择连接写入,不会一直使用一个连接写入 'table-name' = 'clickhouse_key_words', 'username' = 'default', 'password' = 'default', 'format' = 'json' ); CREATE FUNCTION sex_trans as 'com.dataomnis.example.UdfDemo'; INSERT INTO kafka_page_view SELECT product_id,sex_trans(sex) as sex,province,full_name,click_time FROM page_view; INSERT INTO clickhouse_key_words SELECT province,sex,word,TUMBLE_START(click_time,INTERVAL '30' SECOND) AS stt,TUMBLE_END(click_time,INTERVAL '30' SECOND) AS edt,COUNT(*) ct FROM( SELECT CAST(T.word AS STRING) AS word,v.* FROM kafka_page_view AS v,LATERAL TABLE(wordsplit(full_name)) AS T(word) ) GROUP BY TUMBLE(click_time,INTERVAL '30' SECOND),province,sex,word; -
点击语法检查,对代码进行语法检查。
-
点击保存,保存修改,防止代码丢失。
配置作业调度
-
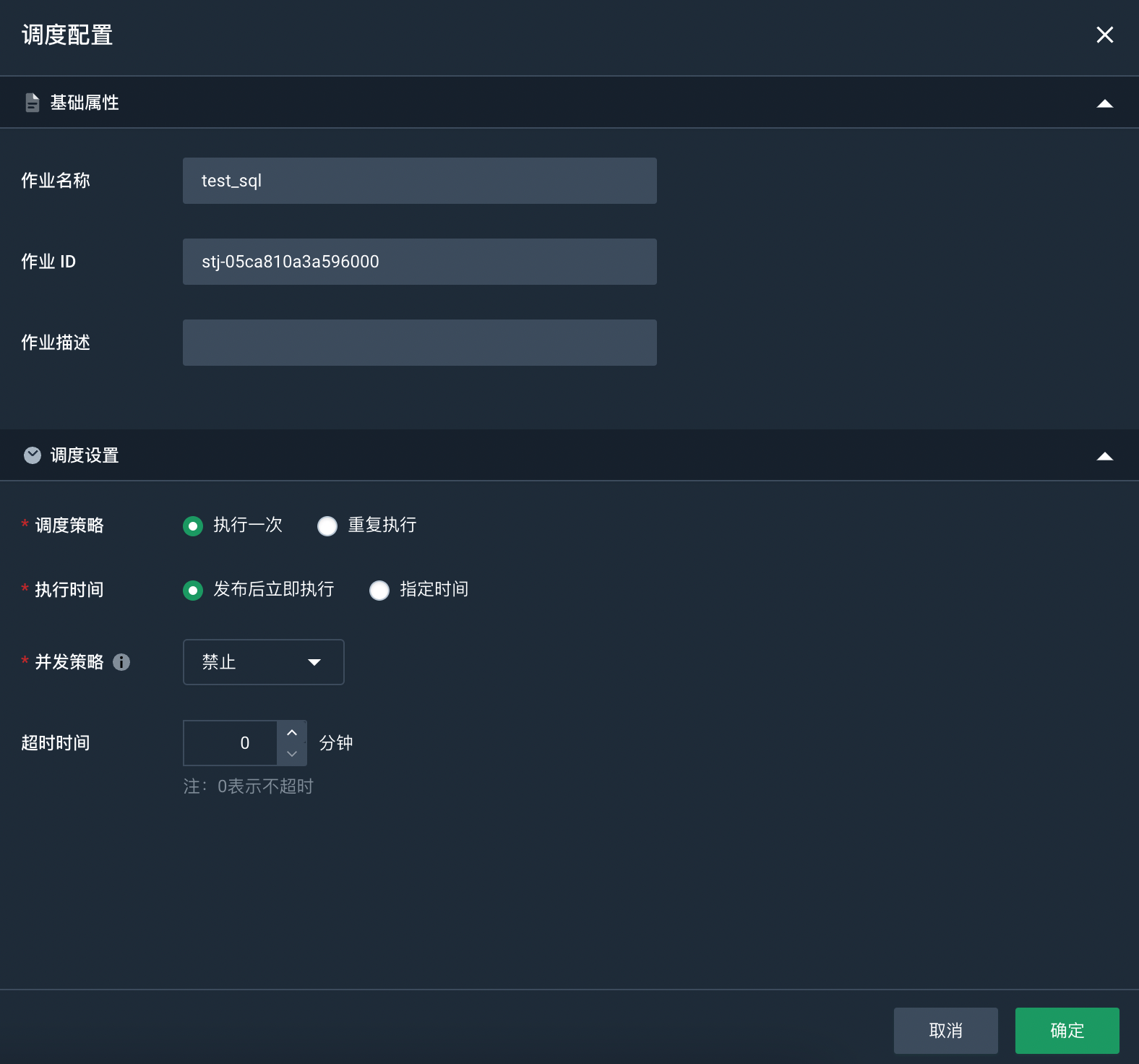
选择已创建好的作业,点击右侧的调度设置,进入调度配置页面。
-
设置调度策略。
本实践选择执行一次,发布后立即执行。若您需要配置为其他调度策略,请参见配置作业调度。
-
设置完成后,点击确定。
配置运行参数
-
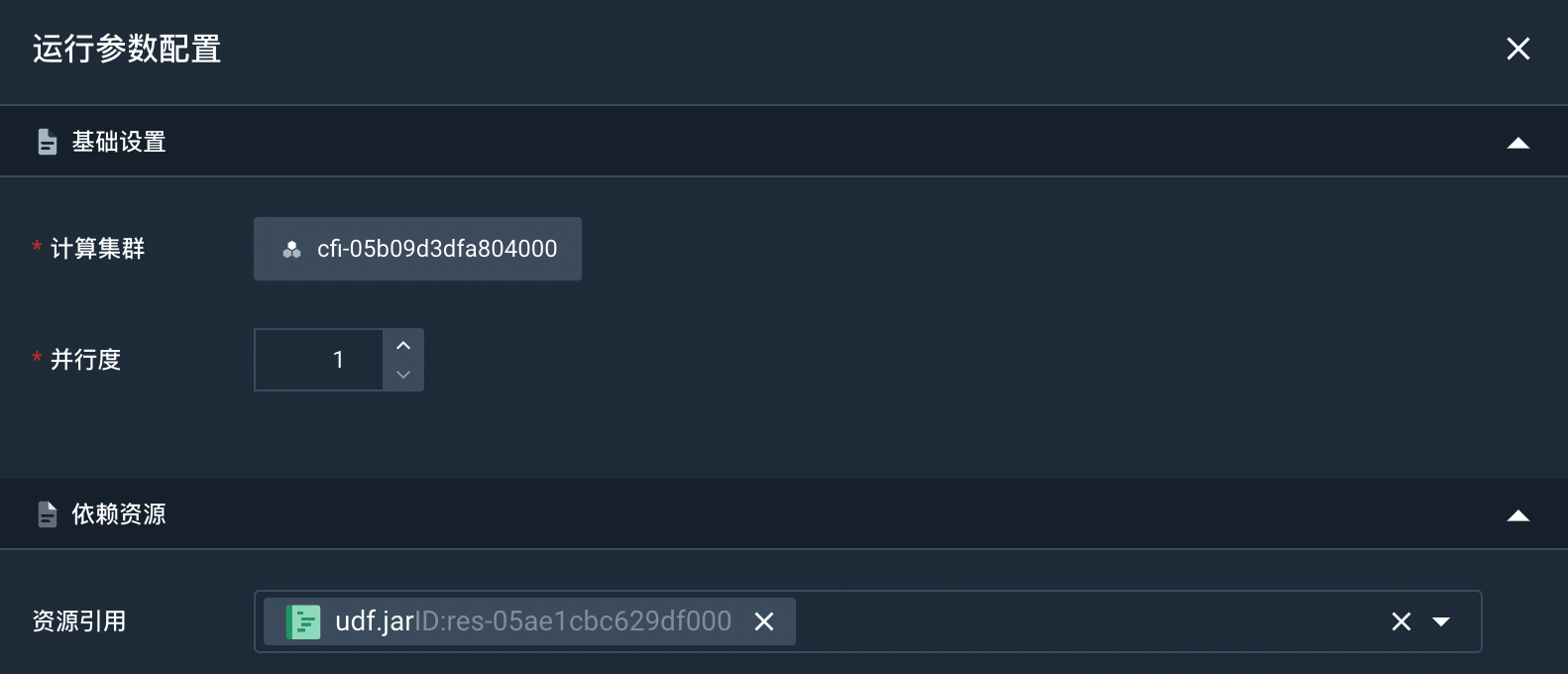
选择已创建好的作业,点击右侧的运行参数,进入运行参数配置页面。
-
配置运行参数。
- 计算集群:在该页面可以查看和修改运行作业的计算集群。
- 并行度:配置作业的并发数,不能为
0,默认为1。 - 依赖资源:选择作业运行所需的函数包以及自定义 Connector 包。本实践无需选择依赖资源。
-
配置完成后,点击确定。
发布作业
完成作业调度和运行参数配置后,您才可以发布作业。
-
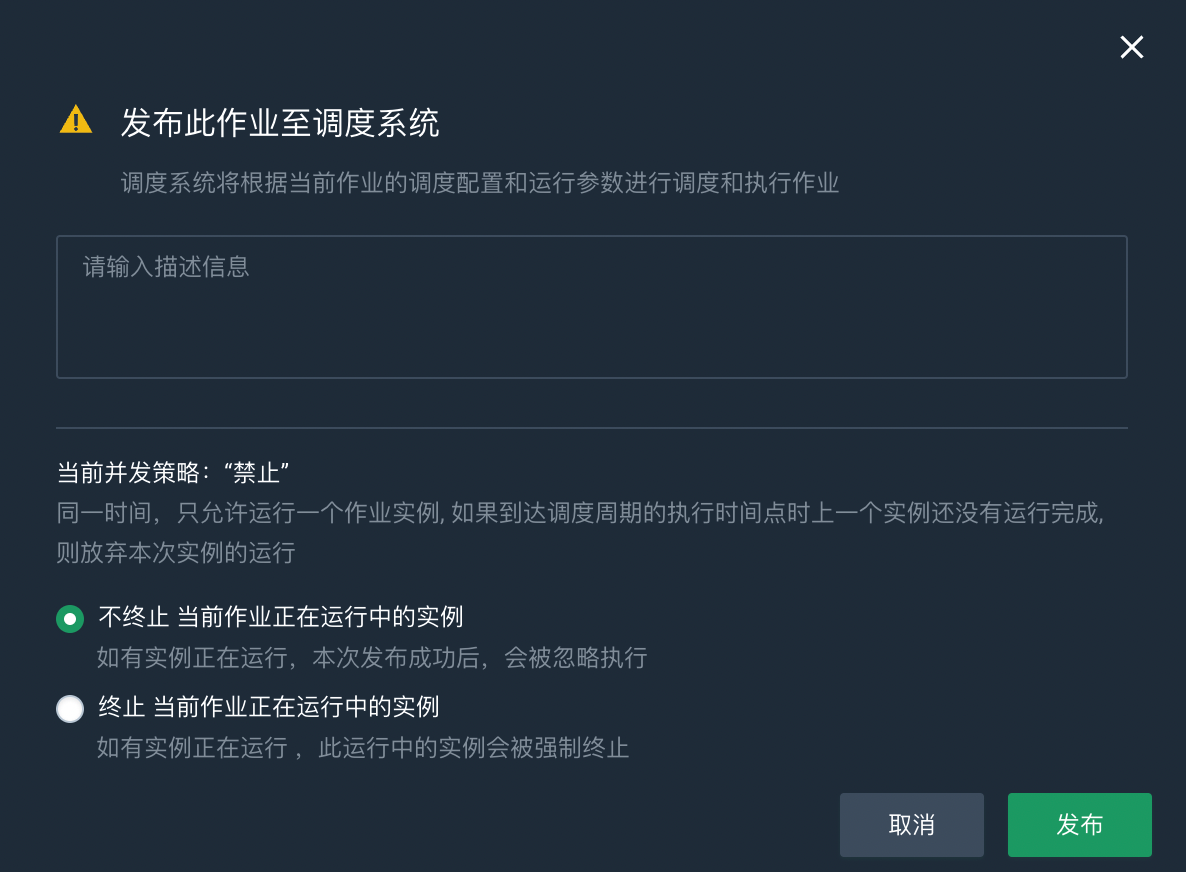
点击发布,弹出发布调度任务对话框。
-
填写作业描述信息。
-
根据实际情况选择是否终止当前作业正在运行中的实例。
如果终止当前作业正在运行中的实例,运行中的作业实例会立即被强制终止。
-
点击发布,发布作业。发布作业时也会对代码进行语法检查,需要一定的时间,请耐心等待。
作业发布成功后,您可以前往运维中心查看已发布作业和作业实例。