数据开发
创建 SQL 作业
-
在目标工作空间选择数据开发 > 作业开发,进入作业开发页面。
-
点击创建作业,进入创建作业页面。
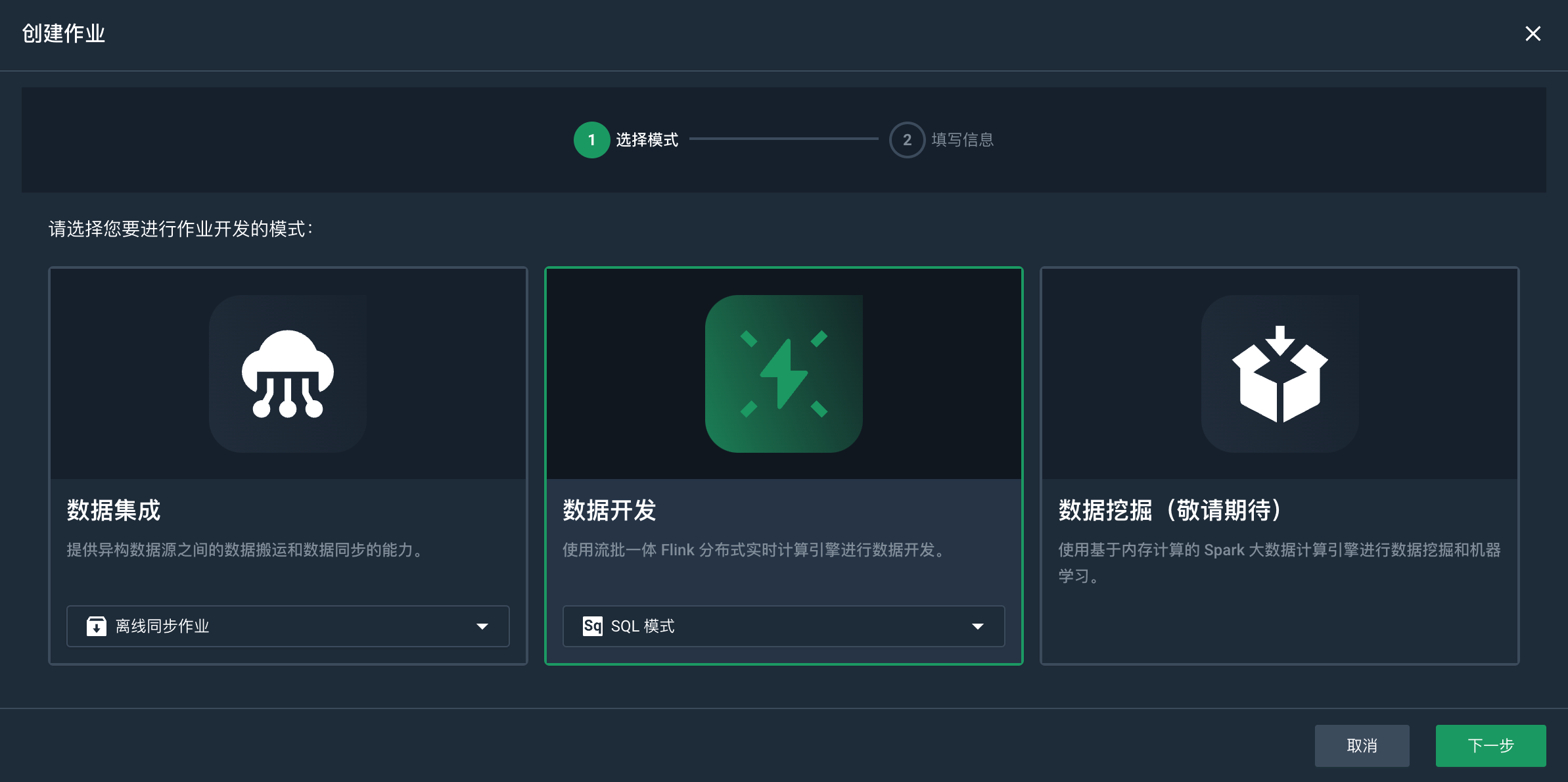
-
选择 SQL 模式。
-
点击下一步,填写作业名称,并选择作业依赖的计算集群。
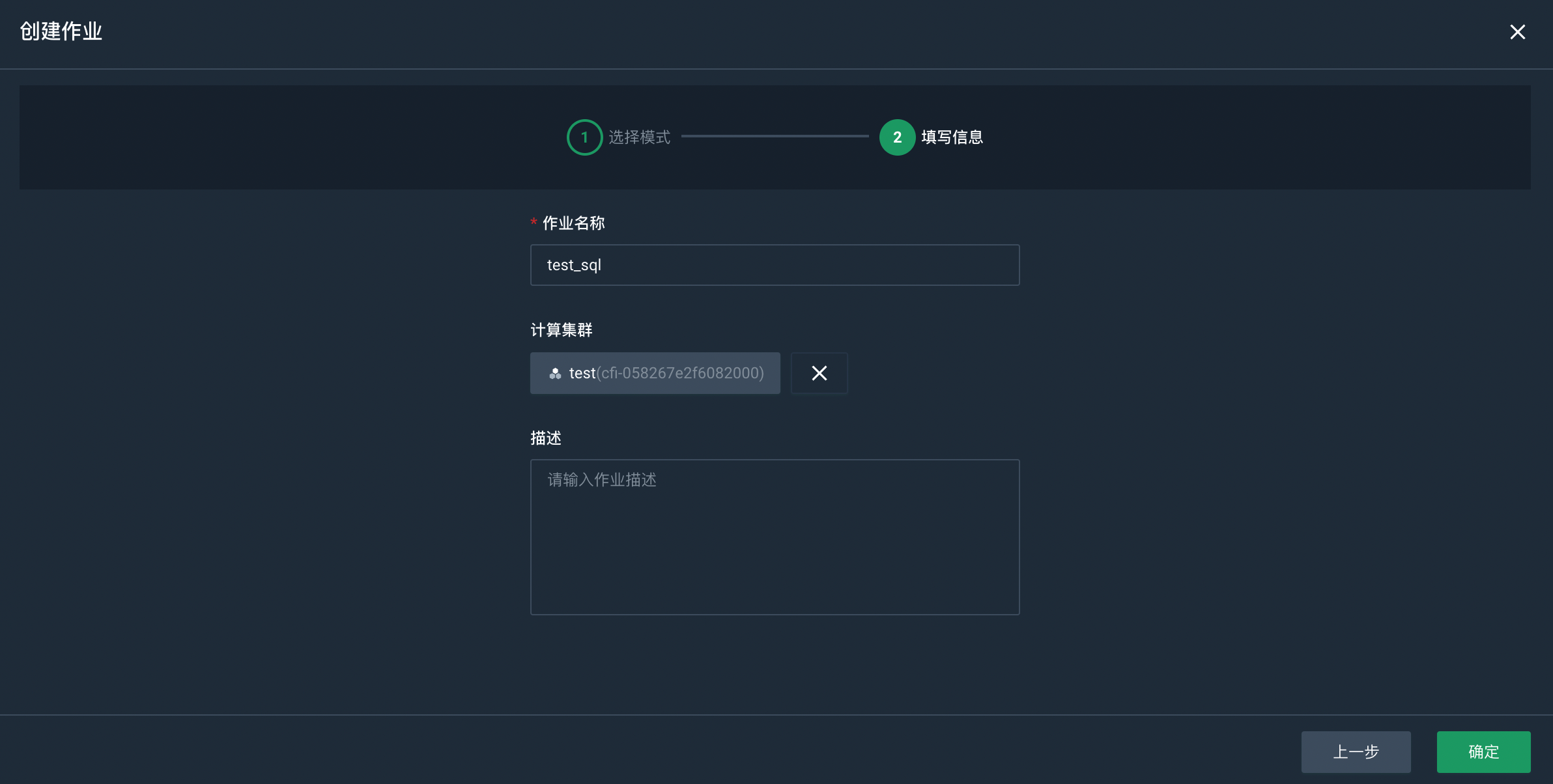
-
配置完成后,点击确定,开始创建作业。
作业创建完成后,默认进入该作业的开发面板。
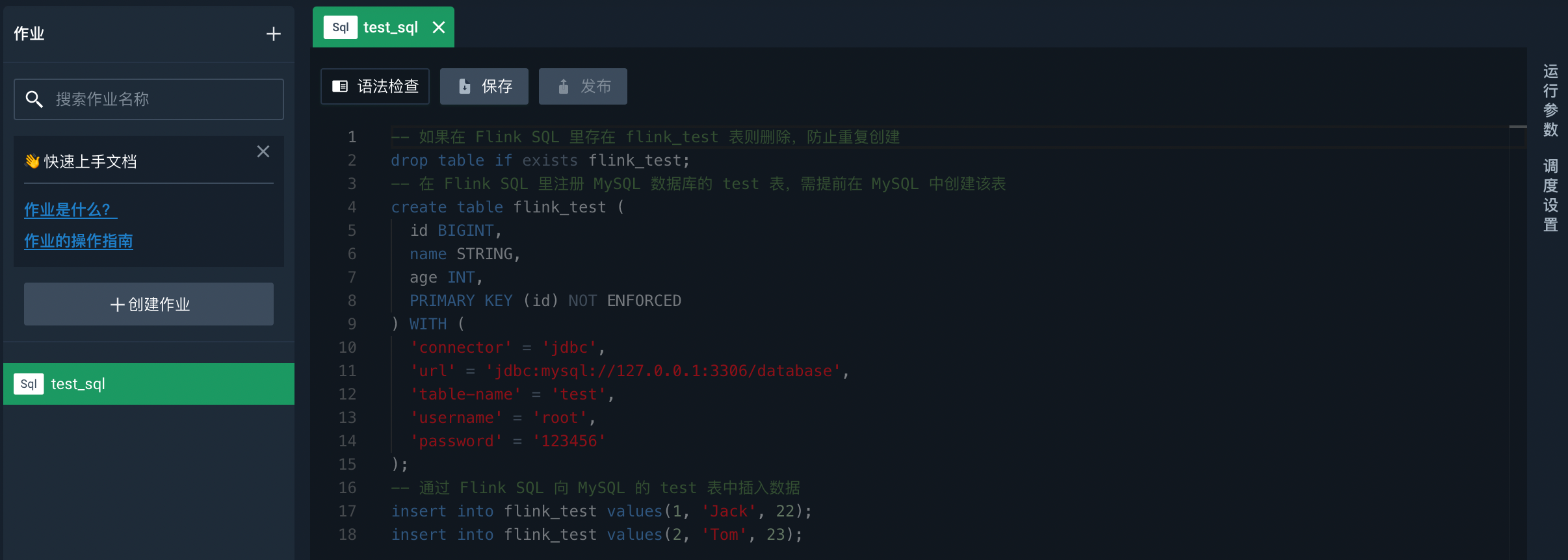
开发 SQL 作业
-
在开发面板中输入以下 SQL 代码,数据源相关参数请根据代码中的注释进行修改。
说明
- 以下 SQL 代码用于建立 flink table 与数据源之间的映射关系;本实践需要提前在 Mysql 中创建好 students 表,并且 students 表包含 id、score、name 列。
- 更多相关参数请参见 MySQL CDC 和 Elasticsearch。
DROP TABLE IF EXISTS students; --删除 flink table 映射 CREATE TABLE students( --建立 flink table 到 mysql table 的映射关系 id INT, name STRING, score INT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', --写入数据到 mysql-cdc 'hostname' = '192.168.100.2', --mysql 连接 IP 地址 'port' = '3306', --mysql 连接端口号 'username' = 'test01', --mysql 连接用户名 'password' = 'Gx12345678@', --mysql 连接密码 'database-name' = 'demo', --mysql 数据库名称 'table-name' = 'students' --mysql 数据库表名称 ); DROP TABLE IF EXISTS es_stu; CREATE TABLE es_stu( id INT, name STRING, score INT, PRIMARY KEY (id) NOT ENFORCED --定义主键规则,开启主键是 upsert 模式;否则是 append 模式。本示例使用 append 模式。 )WITH( 'connector' = 'elasticsearch-7', --输出到es7 'hosts' = 'http://192.168.100.19:9200', --es连接地址 'index' = 'stu', --es的index名;无需提前创建,您可以在此处自定义 'sink.flush-on-checkpoint' = 'true', --checkpoint时不允许批量写入 'sink.bulk-flush.max-actions' = '50', --每批次最多的条数 'sink.bulk-flush.max-size' = '10mb', --每批次累计最大大小 'sink.bulk-flush.interval' = '1000', --批量写入的间隔(ms) 'connection.max-retry-timeout' = '1000', --每次请求的最大超时时间(ms) 'format' = 'json' --输出数据格式,目前只支持 'json' ); INSERT INTO es_stu SELECT id,name,score FROM students; -
点击语法检查,对代码进行语法检查。
-
点击保存,保存修改,防止代码丢失。
配置作业调度
-
选择已创建好的作业,点击右侧的调度设置,进入调度配置页面。
-
设置调度策略。
本实践选择执行一次,发布后立即执行。若您需要配置为其他调度策略,请参见配置作业调度。
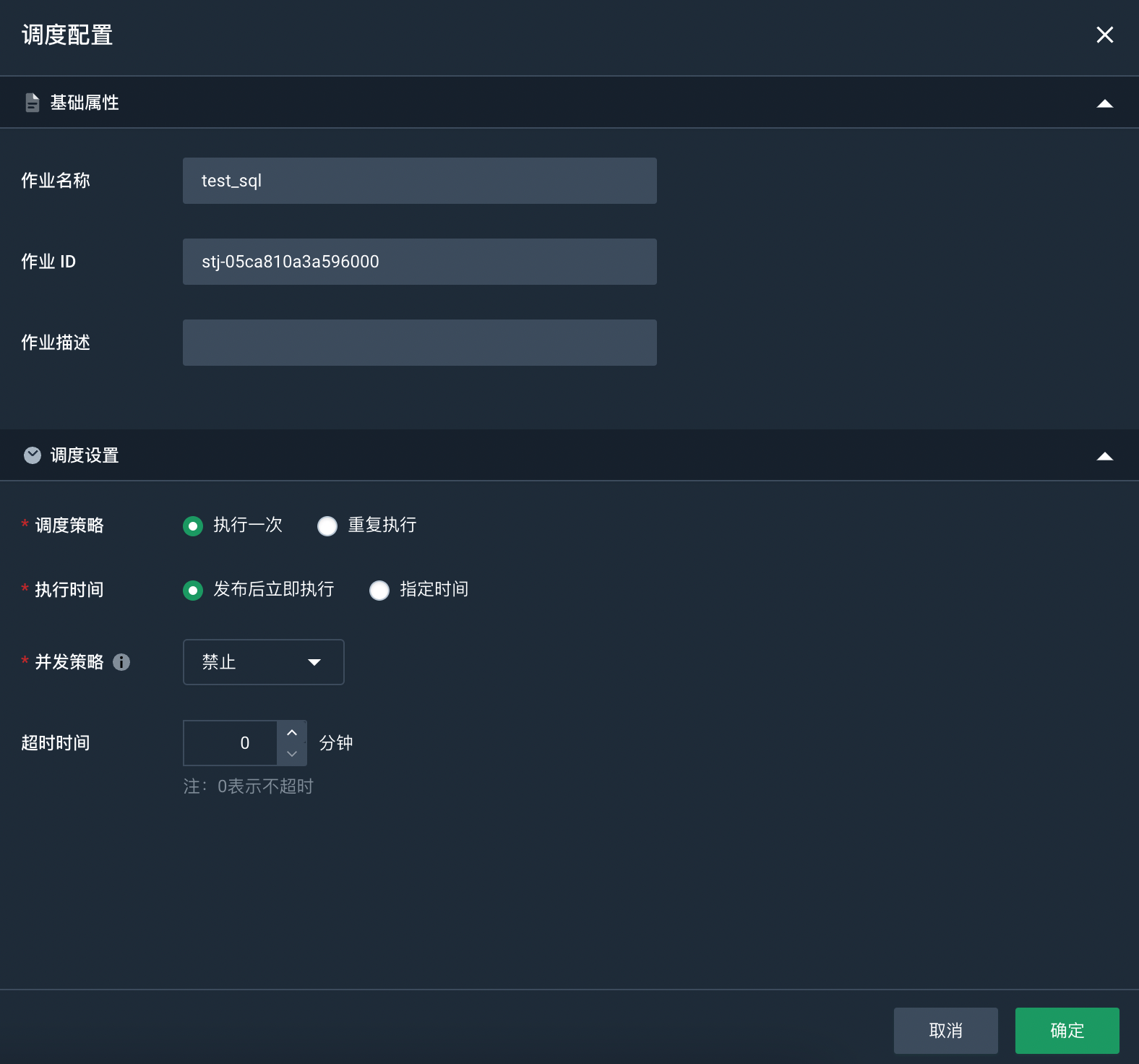
-
设置完成后,点击确定。
配置运行参数
-
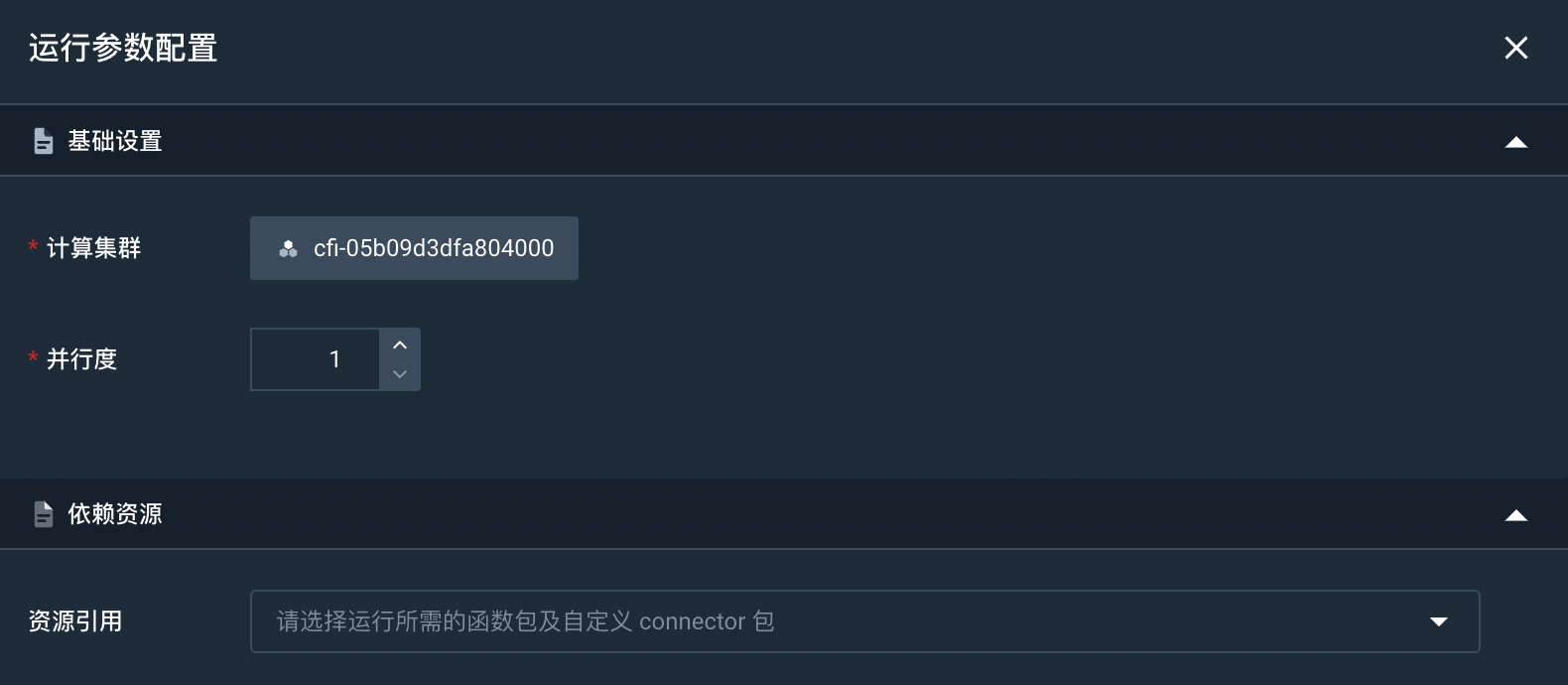
选择已创建好的作业,点击右侧的运行参数,进入运行参数配置页面。
-
配置运行参数。
- 计算集群:在该页面可以查看和修改运行作业的计算集群。
- 并行度:配置作业的并发数,不能为
0,默认为1。 - 依赖资源:选择作业运行所需的函数包以及自定义 Connector 包。本实践无需选择依赖资源。
-
配置完成后,点击确定。
发布作业
完成作业调度和运行参数配置后,您才可以发布作业。
-
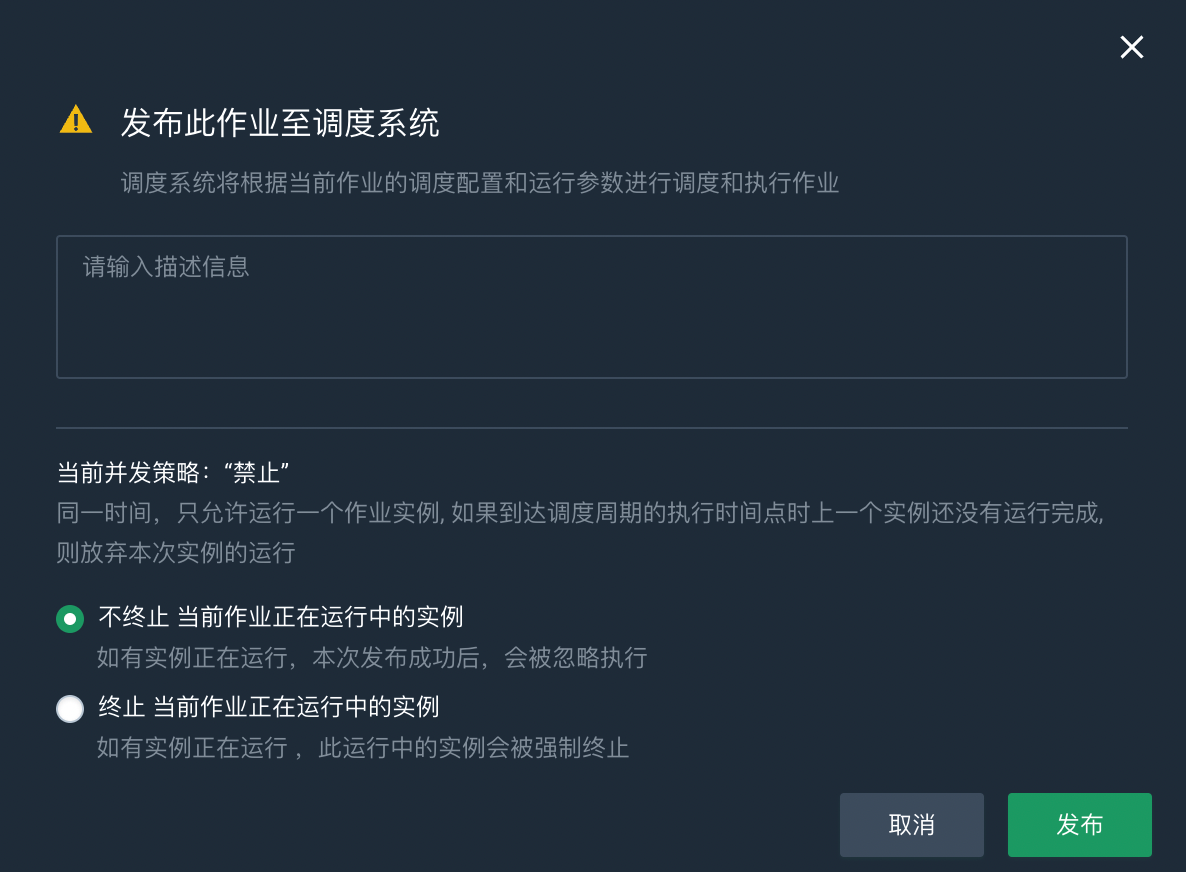
点击发布,弹出发布调度任务对话框。
-
填写作业描述信息。
-
根据实际情况选择是否终止当前作业正在运行中的实例。
如果终止当前作业正在运行中的实例,运行中的作业实例会立即被强制终止。
-
点击发布,发布作业。发布作业时也会对代码进行语法检查,需要一定的时间,请耐心等待。
作业发布成功后,您可以前往运维中心查看已发布作业和作业实例。
说明
本实践的示例是一个实时持续的过程,所以作业实例的状态会一直显示
运行中,除非您手动终止该作业实例。